Train, But Verify
Created October 2020
Machine learning (ML) systems have the power and potential to greatly expand our capabilities. Unfortunately, these systems are vulnerable to attacks that seek to exfiltrate information and interfere with their decisions. Attacks on ML systems can make them reveal sensitive information, learn the wrong thing, or do the wrong thing – thereby undermining the system’s capabilities.
Train, But Verify protects ML systems by training them to act against two of these threats at the same time and verifying them against realistic threat models.
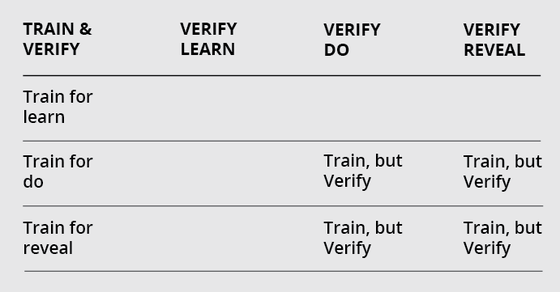
Enforcing Security Policies: Learn, Do, and Reveal
The Beieler Taxonomy [1] categorizes three ways an ML system can be attacked. The three matching security policies for a defender to enforce are:
- LEARN the right thing, even from data that’s influenced by adversaries.
- DO the right thing, even with adversarial examples present.
- Never REVEAL sensitive information about the model or data.
The DoD needs ML systems that are resilient to attack. According to the DoD AI Strategy [2], their goal is to “Train AI Systems to be more resilient to hacking and adversarial spoofing, as well as ‘novel approaches to testing, evaluation, verification, and validation’ of the desired properties of these AI Systems.”
Attacks that reveal useful information
Most work on defending ML systems focuses on enforcing a single security policy. Unfortunately, these policies cannot always be implemented simultaneously, leaving vulnerabilities that attackers can exploit. For example, in models trained on CIFAR 10 to enforce a “do” policy [3, 4], adversaries with both full-model access and query-only access can recover the presence of riders on horses (about 20% of the class).

Train, But Verify: Defending Multiple Security Policies
Protecting ML systems requires more than one security policy to be enforced at a time. The goal of Train, But Verify is to help AI systems become more resistant and resilient to attack. We take a two-pronged approach to protecting ML systems:
- TRAIN secure systems by training ML models to enforce at least two security policies.
- VERIFY the security of ML systems by testing them against realistic threat mod-els across multiple policies.
Our research focuses on training ML systems to enforce both a "do" policy and a "reveal" policy, then verifying their enforcement against a set of real-world threat models. This will improve the security and robustness of ML systems.
Mitigating Threats to ML Systems
Robustness
- Use TRADES adversarial training to derive other ML methods
- Enforce smoothness of ML classification via TRADES and other adversarial methods
- Visualization
- Smoothness not sufficient for recognizability
Privacy
- Model access not needed to reveal training data characteristics
Required Conditions
- Tentatively necessary: minimax estimation
- Not sufficient: Local or global Lipschitz continuity
Further Areas of Investigation
- Determine what are sufficient conditions for recognizability (e.g., smoothness, orientation of decision boundary)
- What does “useful” mean? This will require more collaboration and exploration.
Looking Ahead
Future work on Train, But Verify includes
- providing proof-of-concept defenses that either enforce multiple policies (“do” and “reveal”), or trade off between those policy goals
- building proof-of-concept tooling to verify that “do” and “reveal” policies are enforced across multiple security policies
Learn More
Train but Verify: Towards Practical AI Robustness
•Video
This short video provides an introduction to a research topic presented at the SEI Research Review 2021.
WatchTrain but Verify: Towards Practical AI Robustness
•Presentation
Train, but Verify is an effort to develop an AI Engineering process to train AI systems to have specific robustness properties.
Learn More