Juneberry
Created March 2022
Juneberry automates the training, evaluation, and comparison of multiple ML models against multiple datasets. This makes the process of verifying and validating ML models more consistent and rigorous, which reduces errors, improves reproducibility, and facilitates integration.
Machine learning (ML) is increasingly being applied to cybersecurity, logistics, threat detection and analysis, and other critical, data-intensive operations. Evaluating machine learning models to improve results is challenging but necessary in these fields where precisely predicting outcomes is essential.
The Juneberry system facilitates machine learning experimentation by helping users train and compare machine learning models that may have different architectures, datasets, and/or hyperparameters. Various configuration files, in JSON format, control the characteristics of the experiment, such as which models to use, training datasets, evaluation datasets, and the types of reports and graphics to generate for comparison purposes. By automating training and evaluation, Juneberry can improve robustness and security, qualities foundational to AI engineering.
Evaluating ML Models is Key to ML Adoption
Successfully adopting ML requires finding the best model that represents an organization’s data and determining how well the selected model will work for the organization in the future. To ensure ML adoption will be effective, developers must compare the performance of several ML models that may have different architectures, hyperparameters, and training data pipelines. This is not a simple task: since the order of data affects a model’s learned behavior, every training and testing dataset must be presented identically to every model; to control the comparison, ML models must be trained and tested on the same exact datasets; and to ensure the correctness of results, evaluation criteria must be consistent across models.
The SEI’s Artificial Intelligence (AI) Division determined that automation was a solution to the challenges involved in this process of evaluating and comparing multiple ML models against multiple datasets. An automated framework could improve the accuracy of training, comparing, and evaluating ML models, leading to reduced errors, improved reproducibility, and better integration. This would in turn improve ML adoption and the value ML brings to organizations.

Developing an Automated Framework to Evaluate ML Models
Researchers at the SEI’s AI Division have developed Juneberry, a tool to improve the automation, evaluation, and comparison of multiple ML models to make these predictions as accurate as possible. It automates loading and preparing training data, constructing and executing models, generating inferences from test datasets, producing reports, and organizing and managing different types of output. Juneberry is open-source and can be cloned or downloaded via GitHub.
For ML Developers and ML Researchers
With Juneberry, ML developers can set up structured experiments that directly compare the performance of multiple ML models with different backends. Developers define the metrics for training and evaluating these ML models. This rigorous approach to model verification and validation reduces potential errors and makes it easier to reproduce results.
For Organizations
Output from Juneberry can feed into existing software development workflows. This makes it easier to integrate the best-performing ML models into applications and deploy them across the enterprise.
Key Features
Juneberry includes the following key features:
- configuration-driven. Users spend more time designing platform-independent experiments and less time writing, testing, and debugging code.
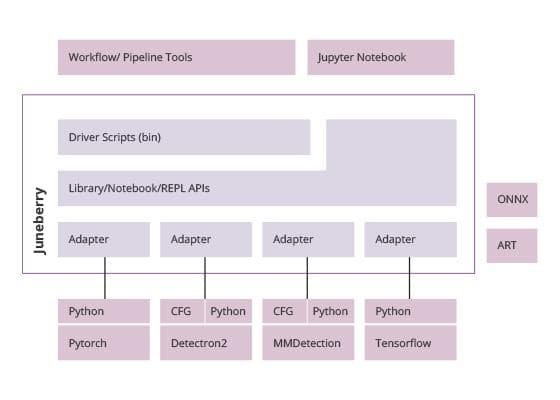
- supports multiple ML backends. Juneberry provides a level playing field suitable for making comparisons between different types of ML models. Juneberry supports TensorFlow, PyTorch, Detectron2 and MMDetection, and ONNX.
- emphasizes reproducibility. Juneberry’s structured approach to training and testing allows experiments to be easily repeated and their results reproduced.
- evaluates and compares multiple models at a time. The size of experiments is limited only by your computing resources.
- reduces the potential for error. Automation handles the complexity of working with dozens (or even hundreds) of models and their outputs.
- exposes execution tasks. This makes it easier to integrate Juneberry with existing pipelines and workflow tools such as doit.
- supports prototyping. Juneberry is compatible with prototyping in Jupyter notebook environments.
Software and Tools
Juneberry
Juneberry automates the training, evaluation, and comparison of multiple ML models against multiple datasets.
Learn More