Expecting the Unexpected: Monitoring for Drift in ML Systems


Imagine the following scenario: you and a team of cyber experts have been tasked with protecting your organization from cyberattacks. You’ve developed a machine learning (ML) model to screen incoming and outgoing traffic. You feel you can rest easy, as your model achieves near-perfect performance during test and evaluation. One day, you are awakened by a frantic call from your CEO—your customers’ private data have been leaked. How could this happen? you think to yourself, as you begin investigating why your model failed to stop this attack.
This situation is not merely hypothetical. Studies have found that models that were once highly effective at detecting malicious activity become significantly less effective as attack patterns evolve (in Android applications, encrypted traffic, and malware). As ML and other artificial intelligence (AI) models become pervasive, it is increasingly important to ensure these models continue to perform well when deployed. For cybersecurity models, this means they should be able to adapt to counter intelligent adversaries as they evolve their techniques. Continuously monitoring performance for signs of drift and retraining, when necessary, can be essential to avoid significant and costly losses.
At the Software Engineering Institute (SEI), we have a long history of work at the forefront of cybersecurity and machine learning, from establishing C/C++ secure coding standards to founding the first AI security incident response team. While ML is a potentially transformative technology for securing information systems, the cyber landscape is ever changing because the behaviors of users, attackers, and information systems evolve over time. If not addressed, these changes can degrade the performance of even the best ML-based defenses. Measures need to be in place to detect and respond to drift before real-world harms are enacted.
In this post, we describe what causes drift, discuss how to detect it, and provide a case study.
What Is Drift?
Things change over time. Hardware and software systems are updated, humans adopt new behaviors, and environments shift. Adversaries adapt their tactics. Changes that affect data used or predicted by an ML model are called drift. There are three primary types of drift: data drift, concept drift, and label drift. We illustrate these using an ML-based email classifier as an example:
ML-based Email Classification
Classification ML models use inputs, or features, to predict outcomes, or labels. Supervised learning classification models learn relationships between features and outcomes in training data and assume these relationships still hold when the models make predictions in production.
For our hypothetical cybersecurity ML model, the model is trained using emails labeled as phishing or benign. Each email has associated features, such as whether a hyperlink is present and the number of typos in the text body. The model learns the relationships between the features and labels in training data to predict whether new, previously unseen emails are phishing or benign. The predictions on the new emails are only accurate if the learned relationships remain the same as in the training data.
Concept drift is defined by changes in the relationships between features and outcomes. Concept drift can be particularly problematic because the learned relationship between features and outcomes may no longer hold. Concept drift is highly relevant in settings where adversarial actions are common. When adversaries aim to evade detection, they may modify their behaviors, for example to better mimic benign users. For example, adversaries sending phishing emails may discover emails containing hyperlinks are blocked by our phishing classifier model. To circumvent this, adversaries may stop including hyperlinks in phishing emails, altering the relationship between hyperlink-containing text and the probability an email is a phishing attempt (Figure 1, Panel A).
Data drift—sometimes called feature or covariate drift—refers to changes in the distributions of one or more features over time. Data drift alone does not affect relationships between features and outcomes. For a classifier, data drift occurs when something affects all classes equally. For our email classifier, benign and phishing emails incorporating text written by large language models (LLMs) could cause data drift by reducing the average number of typos in the text (Figure 1, Panel B).
Label drift refers to changes in the distribution of outcomes. For classifier models, label drift indicates the proportion of observations in each class has changed. Label drift can negatively impact classification models that are sensitive to class imbalances. For the phishing email classifier, a change in the proportion of emails that are phishing attempts would be an example of label drift (Figure 1, Panel C).
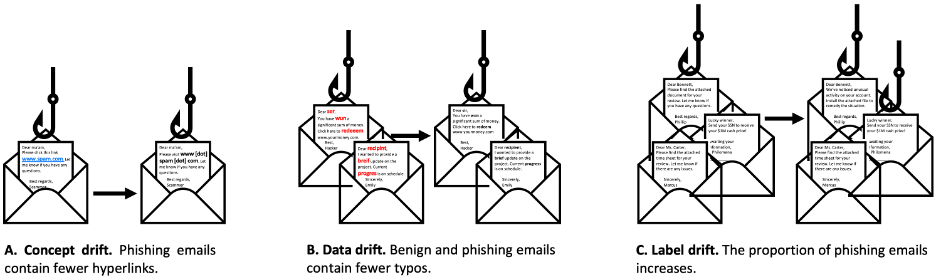
These types of drift often co-occur. For example, a change in user behavior could affect the overall distribution of a feature (feature drift) as well as the relationship between that feature and the outcome class (concept drift). Because these different drift types can have varying impacts on production-level ML models, it is important to understand what types of drift are occurring.
How Can We Detect Drift?
While drift can cause model performance degradation, there are techniques to identify and reduce degradation. One step to secure ML models against drift is to implement drift detectors. These methods identify when the operating environment has changed and issue alerts, enabling timely model retraining. Drift detection has been noted as a CISA technology of interest and is listed as a required step in the lifecycle of AI systems in the DoD manual Operational Test and Evaluation and Live Fire Test and Evaluation of Artificial Intelligence-Enabled and Autonomous Systems.
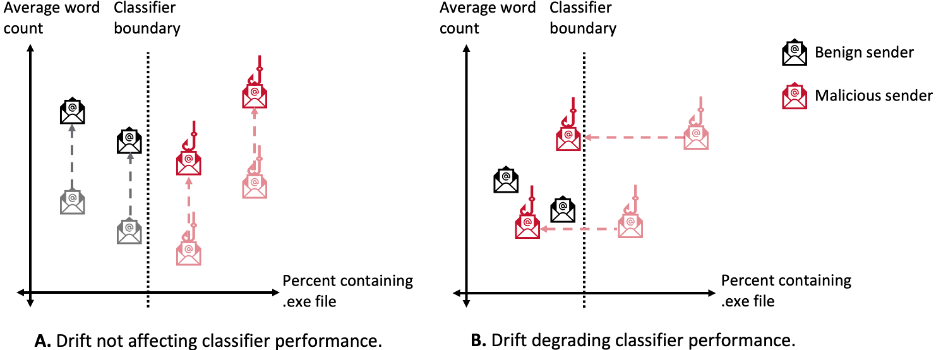
Drift can be detected in two ways: (1) by monitoring for changes in performance metrics or (2) by monitoring for changes in data distributions. Changes in performance metrics, such as accuracy or root mean squared error (RMSE), indicate a discrepancy between training and deployment environments. Monitoring for changes in ML model performance metrics directly is appealing because model performance is what an analyst aims to optimize; drift that does not negatively impact model performance can be safely ignored. Figure 2 illustrates drift that does not affect the classifier (Panel A) and drift that degrades classifier performance (Panel B).
In many applications, labeled production data is not available. In these cases, drift can only be detected by monitoring for changes in the distributions of the features. A simple method of monitoring for drift in unlabeled data is to monitor each feature individually. A significant distributional change in a feature can indicate the production environment has drifted from the training environment.
A limitation of this approach, particularly with high-dimensional cyber data, is that drift in uninformative features that does not negatively impact ML model performance may nevertheless trigger an alert.
To avoid these false alarms, drift detection methods have been developed to specifically target drift that impacts model predictions. One such method, a technique called margin density drift detection (MD3), defines a margin around a classifier’s decision boundary. The margin corresponds to a region where the classifier has low confidence in its class predictions. By establishing a baseline percent of observations falling within the margin, a drift alarm can be triggered when a significant proportion of observations drift in or out of this margin. In other words, MD3 triggers an alert when the model encounters an unexpectedly high number of cases that are difficult (or easy) to classify. Since the decision boundary determines how a classifier assigns labels, MD3 only signals an alarm for drift that could affect model predictions.
Case Study: DNS Data Exfiltration
At the SEI, we conducted a case study using a DNS exfiltration dataset. We selected DNS data exfiltration because it provides a realistic cybersecurity use-case for ML-based detection with an adversary attempting to evade detection.
Data exfiltration poses a serious threat for organizations dealing with confidential or proprietary information. For example, in 2024, hackers executed a large-scale ransomware attack on Change Healthcare, a subsidiary of UnitedHealth Group. The attack compromised sensitive data—including names, Social Security numbers, and health information—of more than 129 million individuals, with a cost to UnitedHealth Group of over $2.8 billion. Other notable recent data leaks include the software company Red Hat’s internal GitLab, the U.S. federal courts case management and electronic case filing system, and TransUnion’s Salesforce account.
While there are many methods of data exfiltration available to adversaries, an often-overlooked route is via DNS. DNS, or Domain Name System, is the protocol used to translate human-readable domain names into IP addresses. Typically, DNS requests are passed from a user’s machine through a firewall to DNS servers, which return a destination IP address. Adversaries who have established a foothold on a user’s machine can take advantage of this process to covertly encode data in the DNS request and recover this data on a DNS server they control. While known malicious servers can be easily blocked by a firewall, it is difficult to pre-emptively block novel ones.
ML classifiers can protect from data exfiltration over DNS to novel DNS servers. Such a classifier can be trained on labeled DNS requests to identify characteristics predictive of data exfiltration. To exfiltrate data over DNS, adversaries encode data in DNS requests sent to adversary-controlled domains. To maximize the amount of data sent, these requests often are long and contain several levels of domains, such as “123abc.3xf2z.example.com.” Because of the unique characteristics of malicious DNS traffic, features such as request length and number of subdomains can be used to train a classifier. While a classifier trained on these features may perform well at first, what happens when an adversary discovers their exfiltration attempts are being thwarted?
Simulation Description
The dataset contains benign DNS requests as well as malicious DNS requests exfiltrating data. Of the malicious requests, some were unobfuscated—the DNS requests were created without any attempt to hide the malicious activity—and the rest were obfuscated. The obfuscation methods include shortening the DNS request length, reducing the entropy of the DNS request, and increasing the time between subsequent requests. We sampled from these data to create two datasets: a pre-drift dataset containing labeled benign and unobfuscated exfiltration DNS requests and a post-drift dataset containing benign and obfuscated exfiltration DNS requests. We trained a random forest classifier on a subset of the pre-drift dataset and calibrated an MD3 detector. We then sampled the remainder of the pre-drift dataset, simulating 40 days of pre-drift data, and sampled from the post-drift dataset, simulating 40 days of post-drift data.
Results
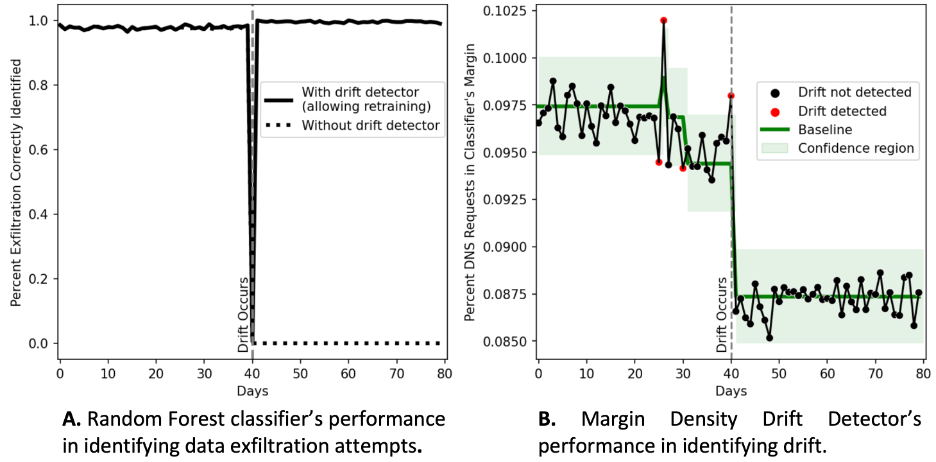
We first checked the random forest classifier’s performance on the pre-drift data. It performed very well, accurately detecting nearly all exfiltration attempts (the dashed line in Figure 3, Panel A before day 40).
Next, we checked the classifier’s performance on the post-drift data. The performance plummeted: exfiltration attempts were no longer detectable (dashed line Figure 3, Panel A after day 40).
We implemented an MD3 detector to test whether it could properly detect the drift. The detector triggered a small number of false positives before drift began (the red points before day 40 in Figure 3, Panel B) and immediately detected drift once it occurred (the red point at day 40 in Figure 3, Panel B).
The performance of the exfiltration detector varied greatly when implementing a drift detector with retraining. Following the onset and detection of drift, the classifier was retrained and regained its high performance on the post-drift data (see the solid line in Figure 3, Panel A, after day 40).
This case study demonstrates that drift detectors accompanied with model retraining can be an effective way to maintain well-performing ML models in dynamic environments.
Deploying ML Solutions in the Presence of Change
ML-powered technologies are invaluable in the defense against cyber attackers. By learning patterns, ML models can help protect against novel attackers. However, ML cyber defenses are susceptible to adversaries who modify their behaviors to mimic benign users.
One way to secure ML models against drift is through deployment monitoring. When drift is detected, an ML model can be retrained on the new data, updating the learned patterns and improving model performance. We found that MD3 is an effective drift detection technique for cyber data because it can be adopted for a range of ML models, does not require labeled data, and is not resource intensive.


More By The Authors
PUBLISHED IN
Artificial Intelligence EngineeringGet updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedGet updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed